
Hao Li
Zhien Zhang
Zhien Zhang

2,* and
Zhe-Ze Zhao
Zhe-Ze Zhao
College of Chemistry, Sichuan University, Chengdu 610064, ChinaWilliam G. Lowrie Department of Chemical and Biomolecular Engineering, The Ohio State University, 151 West Woodruff Avenue, Columbus, OH 43210, USA
School of Life Sciences and State Key Laboratory of Agrobiotechnology, The Chinese University of Hong Kong, Shatin, New Territories, Hong Kong, China
Authors to whom correspondence should be addressed.Current Address: Department of Chemistry and the Institute for Computational and Engineering Sciences, The University of Texas at Austin, 105 E. 24th Street, Stop A5300, Austin, TX 78712, USA.
Processes 2019, 7(3), 151; https://doi.org/10.3390/pr7030151Submission received: 11 February 2019 / Revised: 2 March 2019 / Accepted: 4 March 2019 / Published: 11 March 2019
(This article belongs to the Special Issue Process Modelling and Simulation)With the rapid development of machine learning techniques, data-mining for processes in chemistry, materials, and engineering has been widely reported in recent years. In this discussion, we summarize some typical applications for process optimization, design, and evaluation of chemistry, materials, and engineering. Although the research and application targets are various, many important common points still exist in their data-mining. We then propose a generalized strategy based on the philosophy of data-mining, which should be applicable for the design and optimization targets for processes in various fields with both scientific and industrial purposes.
Data-mining is a strategy for discovering intrinsic relationships and making proper predictions based on statistics from scientifically-collected data [1]. With the rapid progress in machine learning techniques and methodologies in the recent decade [2,3,4,5,6,7], data-mining has become a popular study since machine learning provides an efficient technique for non-linearly fitting the intrinsic relationships between the independent and dependent variables in a mathematical form. Therefore, without knowing the exact physical or empirical form of the relationships among data, machine learning can come up with a non-linear form of math that could precisely predict the trends of data, including interpolation and extrapolation [8,9,10]. Although those non-linear forms do not contain the exact correlation knowledge, a general approximation of data-based machine learning (with both supervised and unsupervised processes [11,12,13]) always shows precise prediction and could address the problem in an easier way.
In recent years, data-mining has been widely applied for solving problems in chemical, materials, and engineering processes, based on the data collected from either experiments or simulations [14,15,16,17]. In many worldwide pressing issues, such as greenhouse gas capture [18,19], catalytic materials design and optimization [20,21,22,23,24,25,26,27,28,29,30,31], and renewable energy studies [32,33,34,35,36,37,38,39], data-mining has shown predictive power for mining the relationships between the intrinsic and extrinsic properties [40,41,42,43,44,45]. Usually, the mission of a data-mining process is to predict (or output) those variables that are difficult to acquire from experiments/simulations by using the easy variables which can be acquired as the inputs. Through a well-fitted non-linear form, the predicted variables can be rapidly outputted with the inputs of those independent variables. In other words, a machine learning assisted data-mining process is able to expedite the (i) optimization of engineering processes, (ii) discovery of new functional materials, and (iii) understanding of chemical processes.
Despite a number of studies that have been published in the recent decade, there is no well-established philosophy that provides a standard guideline for doing data-mining. Therefore, in this discussion paper, we are motivated to summarize some recent typical studies of data-mining in the processes of chemistry, materials, and engineering. Based on the brief review, comments, and discussions, we then generalize a simple but useful data-mining strategy for these scientific and application processes, which should ultimately benefit to the standard development of knowledge-based data-mining through a machine learning modeling process.
Due to the high-dimensional variables, trends in the chemical processes are sometimes difficult to understand and predict. For example, a chemical process usually depends on multiple factors, including temperature, pressure, as well as the component and composition of reactants. Previously, to capture the relationships between these independent and dependent factors, a response surface methodology (RSM) was usually applied to fit the trends between the independent and dependent variables with multiple 3-D plots [46]. This method is useful for the design and optimization of chemical and materials processes. However, RSM is only able to deal with very limited independent variables in one model, which is not applicable for higher dimension problems in a big-data scale. To address this issue, artificial neural networks (ANNs), as the most widely used machine learning algorithms, have been applied for the same target, replacing RSM [8,47]. People have found that not only being able to deal with high-dimension problems ANNs also have a generalized approximation capacity and tunable algorithmic architectures, which guarantees that they can exhaustively capture the potential relationships between inputs and output(s) after a proper data training and validation process.
A typical application for mining the trends and properties in a chemical process is the greenhouse gas capture and utilization. In our recent study, it was found that a kernel-based ANN, the general regression neural network (GRNN), is able to properly fit the relationships between the solution properties (temperature, operating gas pressure, component, and concentration of the blended solutions) and the solubility of CO2, based on the literature-extracted experimental data [48]. Afterwards, the trends of CO2 solubility can be predicted with the function of temperature, operating CO2 pressure, concentration, and type of blended solutions (Figure 1). It can be seen from Figure 1 that though the trends are non-linear and usually difficult to be predicted with regular non-linear mathematical forms, a GRNN model trained from representative experimental data is able to capture these trends and provide proper understandings for CO2 capture in solutions. A similar study on predicting CO2 thermodynamic properties is shown in Reference [49], where the inputs of blend concentration, temperature, and CO2 operating partial pressure can be used as inputs and specifically predict the CO2 solubility, density, and viscosity of a solution. Similar studies for mining the gas capture and separation can be found in References [50,51]. In addition to the use of ANNs, Günay et al. used a decision tree model to evaluate the important factors of the reaction activity and selectivity of catalysts during CO2 electro-reduction process (Figure 2) [52]. By extracting a large number of experimental literatures, they classified the catalysts with the best Faradaic efficiency, max activity, or most selective pathway. Other catalytic applications through data-mining can be found in References [53,54]. Since most of the chemical and reaction-related processes are based on temperature, pressure, component, composition, and energetic values, it is expected that the data-mining strategy shown here is general and should be applicable for addressing other similar chemical issues through machine learning.
In terms of mining the materials properties, one of the most typical works is the discovery of nature’s missing ternary oxide compounds, as described by Ceder et al. [55]. They developed a machine learning model based on the crystal structure database and suggested new compositions and structures through a data-mining process. Then, using density function theory (DFT) as the quantum mechanical computation method [56,57], they calculated and confirmed the stability of those suggested ternary oxides (Figure 3). Similar studies can be found in recent References [58,59,60,61]. Due to the complexity of the structural information and the electronic structures of the periodic table elements [62,63,64,65,66,67,68,69,70,71], a challenge of their data-mining is the definition of suitable descriptors as the model inputs. In the past decades, there was a large number of descriptors that have been applied for the machine learning process of chemical and materials systems, such as bond length, bond angle, and group contribution analysis [72]. However, since the structural information is usually dependent on the coordination and reference, it was hard to generalize the methods for more complicated systems. To address these issues and provide a generalized machine learning representation, Behler and Parrinello developed a set of new symmetry functions that converts all the atomistic environments into the terms of pair and angular interactions [73]. Together with an architecture of conventional ANN, the relationship between the atomistic structures and the materials properties (e.g., energy) can be efficiently mined. So far, this Behler-Parrinello representation has proven to be highly effective for capturing the structural information of materials during machine learning, which especially benefits to the data-mining in theoretical chemistry and computational materials based on quantum mechanical calculated data.
Engineering process is somewhat different from the processes of chemistry and materials discussed above. The main reason is that most of the knowledge in engineering are based on various empirical equations, due to the complexity of the systems. Therefore, mining the intrinsic relationships during engineering processes are particularly challenging but also important. A typical study using data-mining method for the optimization and design of engineering applications is proposed by Kalogirou [74], where an ANN was applied to train a small number of data from TRNSYS simulations on a typical solar energy system for industrial engineering. Then, a genetic algorithm (GA) [75,76,77] was employed to estimate the optimum size of parameters based on the results from ANN. Interestingly, the use of GA has shown a promising process that could generate reliable data combinations in a short time (Figure 4). Instead of listing the interpolated trends as discussed above, the GA method is a fast way that could expedites the industrial decision on the processes.
Though a GA method is sufficient for generating a limited amount of data, its strategy sometimes would omit the important possible parameters during design. In addition, being different from materials design (as shown in Figure 3), engineering applications require to operate a larger size of data since the materials types are limited by the finite number of elements. And thus, there are many more different possibilities exist in the design and optimization of engineering processes. To overcome these problems, in very recent years, a high-throughput screening (HTS) method was developed for optimizing the engineering devices and processes (Figure 5) [78,79]. As illustrated in Figure 5, it can be seen that an HTS method can generate a large number of possible combination of inputs at the beginning, then a well-trained ANN can rapidly output the performance of all these possible input combinations. Then all those combinations which predicted with good performance would be recorded in a database as future candidates. Then the experimental process can pick a few of these candidates for testing. In previous studies, it has been shown that a regular ANN (trained with 1~2 hidden layers, respectively, with less than 50 hidden neurons) is able to quickly output thousands of predictions in a relatively short period [78]. More importantly, an HTS method is able to fully mine the trends between input and output variables for engineering processes.
With the case analysis discussed above, we can see that a machine learning assisted data-mining is a powerful technique for fitting the intrinsic relationships in the processes of chemistry, materials, and engineering. In addition, it is clear that there are a couple of important steps for these data-mining. First, the choice of model inputs is important since it should be the independent variables that have potential relationships with the output variable(s). Therefore, the use of descriptors should be carefully selected. Second, since the predictions are usually for interpolation, the database used for machine learning model training should be sufficiently representative and diverse. Otherwise, the model might easily get over-fitted [80]. Finally, for prediction, optimization, and/or design applications, the way to generate new combined input data could be carefully chosen: for new materials design, the combination of different types of elements from the periodic table is a good way to screen all the possible materials which are predicted with high-performances; for targeting a good design with less computational cost, a GA method could help to rationally generate new input combinations; to exhaustively screen all the possible optimization in engineering, an HTS method could be a good strategy since the prediction through an already-trained machine learning (e.g., ANN) model is usually computationally costless [78].
Overall, the general data-mining process remains similar regardless of its applications, as summarized in Figure 6. After data collection, a statistical analysis would evaluate whether the data scale is diverse and representative. Then the most reasonable independent variables can be chosen as the descriptors in the model inputs. By training and validation of the machine learning model, we can evaluate whether the descriptors are suitable for capturing the potential relationships with the output(s). If the model is well-trained, it can be used for further mining of the new properties by performing its predictive power. Those new input combinations generated by GA or HTS can be set as the input of the trained model, and the predictions can be rapidly outputted. Finally, a new database can be constructed by having the original experimental data as well as the predicted data from the well-trained machine learning model.
In the new era of machine learning development, data-mining for processes in chemistry, materials, and engineering has become a popular way to promote efficiency in both scientific and industrial research. In this discussion, we have summarized several typical cases for the optimization and design of chemistry, materials, engineering, and other related applications. We found that though there is a variety of research and application fields, the basic strategy, process, and philosophy of data-mining are highly similar. We then have proposed a generalized strategy for the basic philosophy of data-mining, which should be applicable for the design and optimization targets for the processes in various fields. We also expect that in future studies with larger data-scale in science and industry, some more advanced machine learning (e.g., deep learning) techniques could fulfill the future requirement of data-mining, leading to faster and more efficient scientific development.
Both H.L. and Z.Z. wrote this discussion paper. Z.-Z.Z. provided important insights in the discussion of the paper.
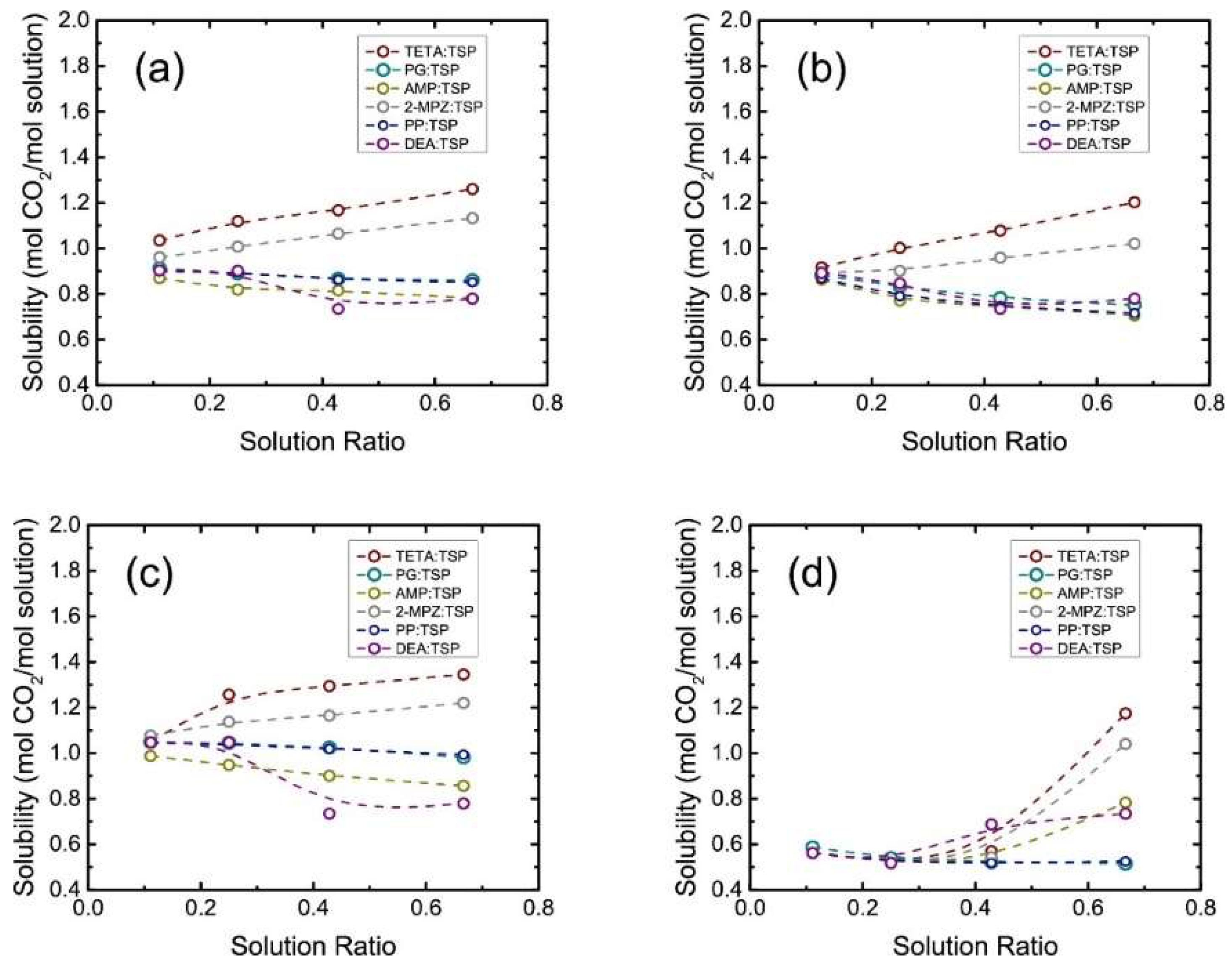
Figure 1. Trends in the CO2 capture in blended solutions, predicted by a well-trained general regression neural network model. (a) T = 303 K, P = 14 kPa, C = 2.5 M; (b) T = 323 K, P = 14 kPa, C = 2.5 M; (c) T = 303 K, P = 42 kPa, C = 2.5 M; (d) T = 303 K, P = 14 kPa, C = 1.5 M. T, P, and C represent temperature, CO2 partial pressure, and concentration, respectively. Reproduced with permission from J. CO2 Util. ; published by Elsevier, 2018 [48].
Figure 1. Trends in the CO2 capture in blended solutions, predicted by a well-trained general regression neural network model. (a) T = 303 K, P = 14 kPa, C = 2.5 M; (b) T = 323 K, P = 14 kPa, C = 2.5 M; (c) T = 303 K, P = 42 kPa, C = 2.5 M; (d) T = 303 K, P = 14 kPa, C = 1.5 M. T, P, and C represent temperature, CO2 partial pressure, and concentration, respectively. Reproduced with permission from J. CO2 Util. ; published by Elsevier, 2018 [48].
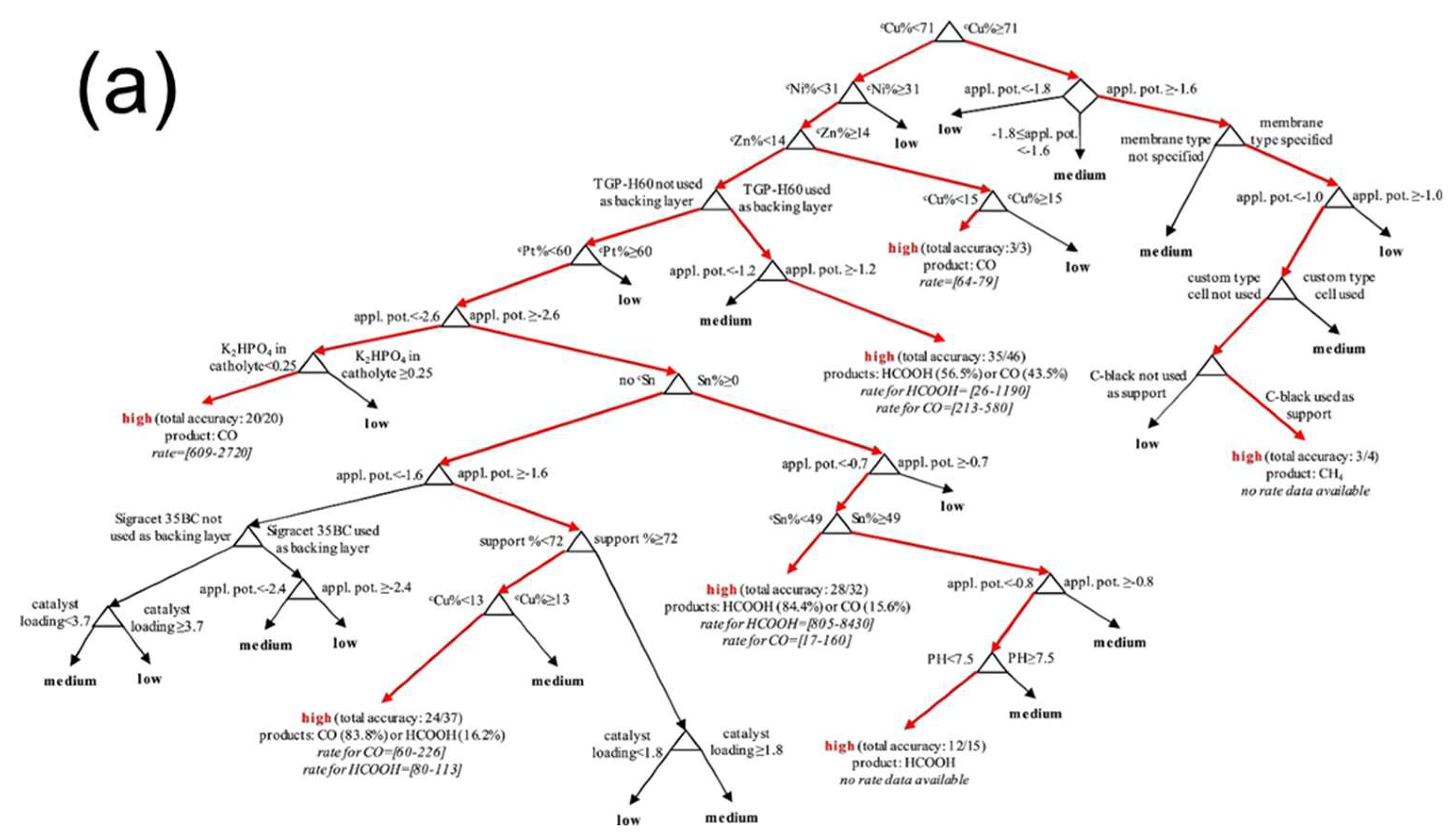
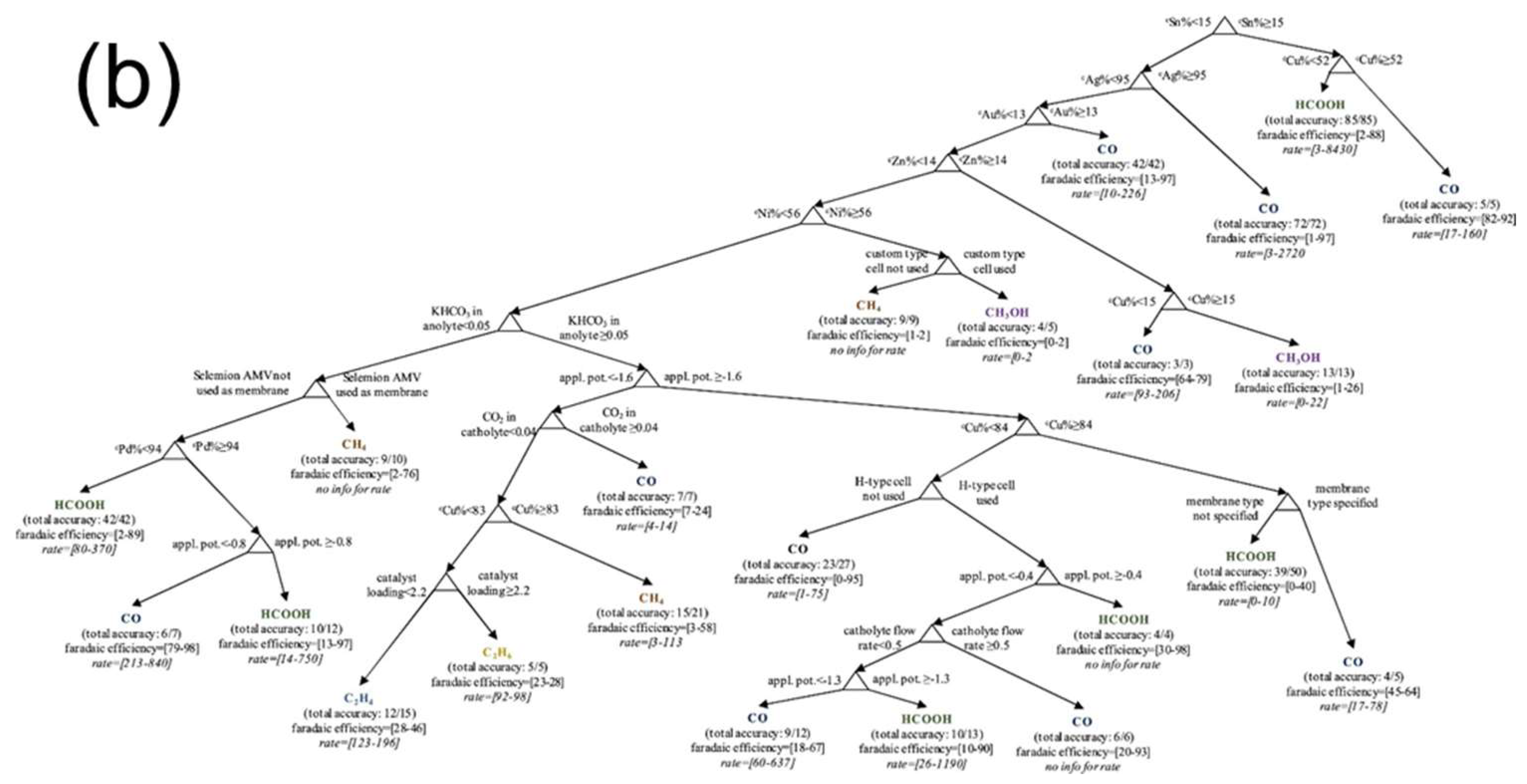
Figure 2. Decision tree analysis for (a) catalysts with maximum faradaic efficiency and (b) catalysts with the highest selective product, for CO2 reduction. Reproduced with permission from J. CO2 Util. ; published by Elsevier, 2018 [52].
Figure 2. Decision tree analysis for (a) catalysts with maximum faradaic efficiency and (b) catalysts with the highest selective product, for CO2 reduction. Reproduced with permission from J. CO2 Util. ; published by Elsevier, 2018 [52].
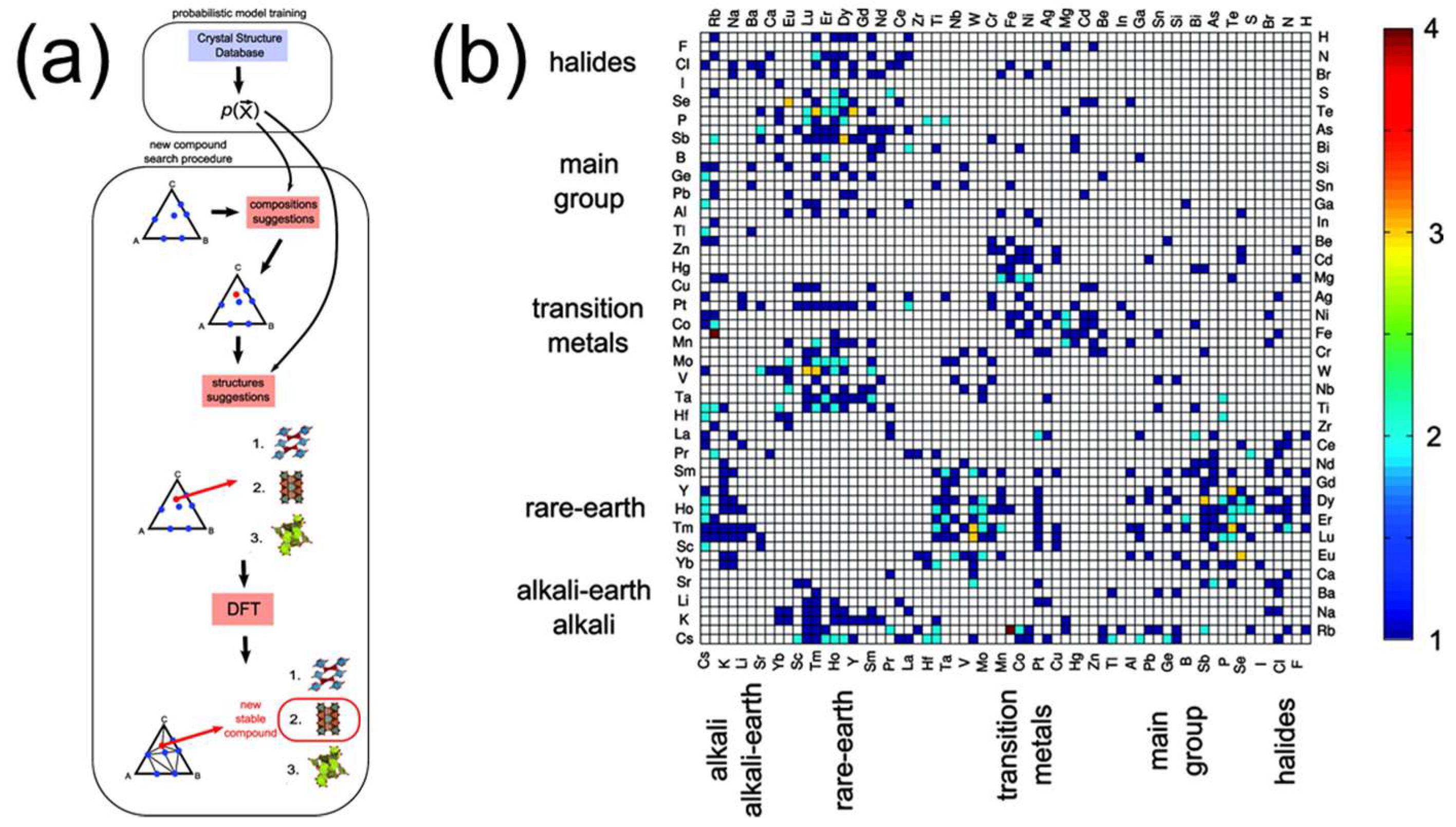
Figure 3. (a) A data-mining compound searching procedure proposed by Ceder et al. (b) Distribution of the newly discovered compounds. Reproduced with permission from Chem. Mater .; published by American Chemical Society, 2010 [55].
Figure 3. (a) A data-mining compound searching procedure proposed by Ceder et al. (b) Distribution of the newly discovered compounds. Reproduced with permission from Chem. Mater .; published by American Chemical Society, 2010 [55].

Figure 4. A genetic algorithm procedure for optimizing the solar energy systems together with a well-trained artificial neural network model. Reproduced with permission from Appl. Energy ; published by Elsevier, 2004 [74].
Figure 4. A genetic algorithm procedure for optimizing the solar energy systems together with a well-trained artificial neural network model. Reproduced with permission from Appl. Energy ; published by Elsevier, 2004 [74].
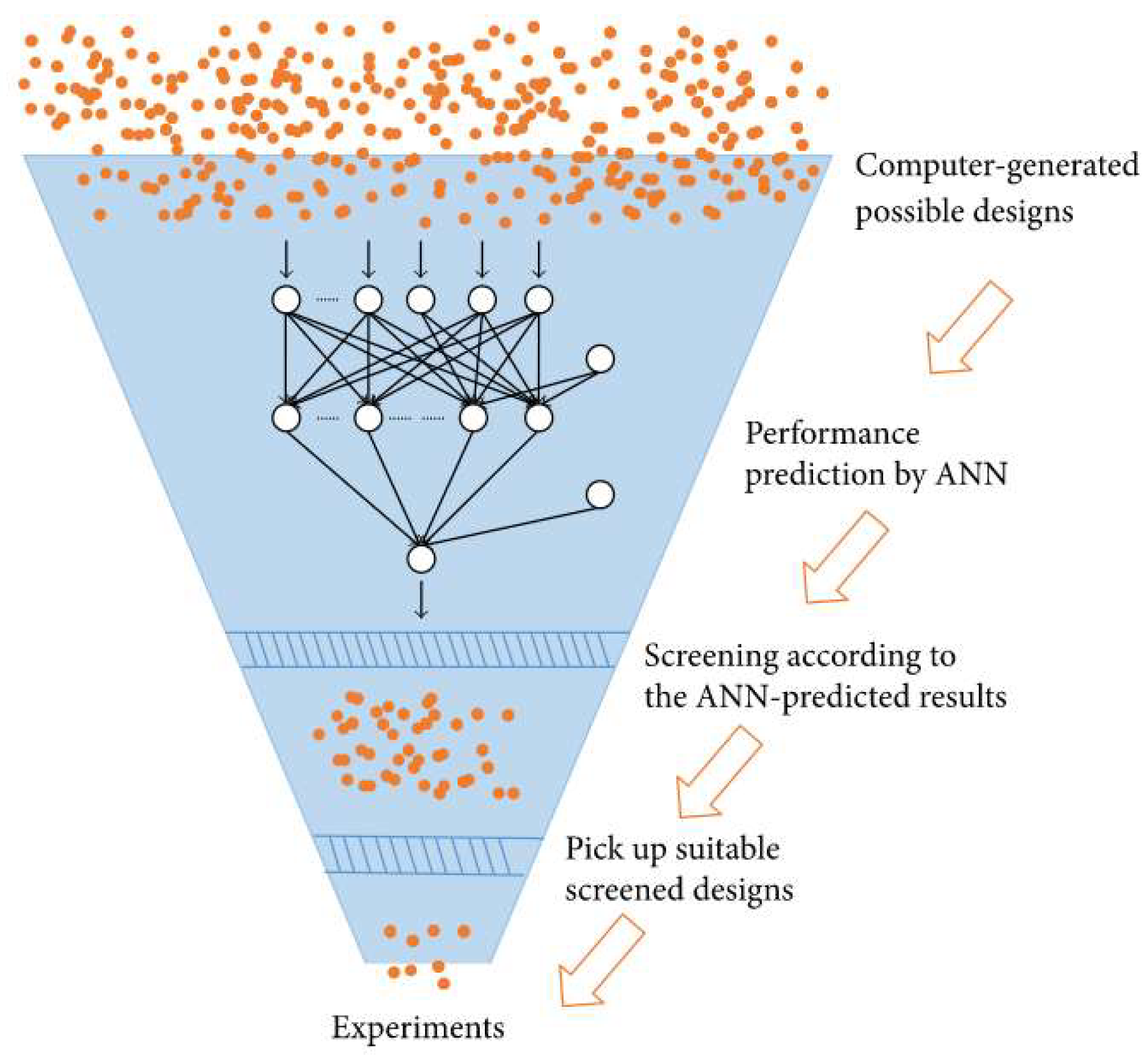
Figure 5. A high-throughput screening process for engineering system optimization. Reproduced with permission from Int. J. Photoenergy ; published by Hindawi, 2017 [78].
Figure 5. A high-throughput screening process for engineering system optimization. Reproduced with permission from Int. J. Photoenergy ; published by Hindawi, 2017 [78].
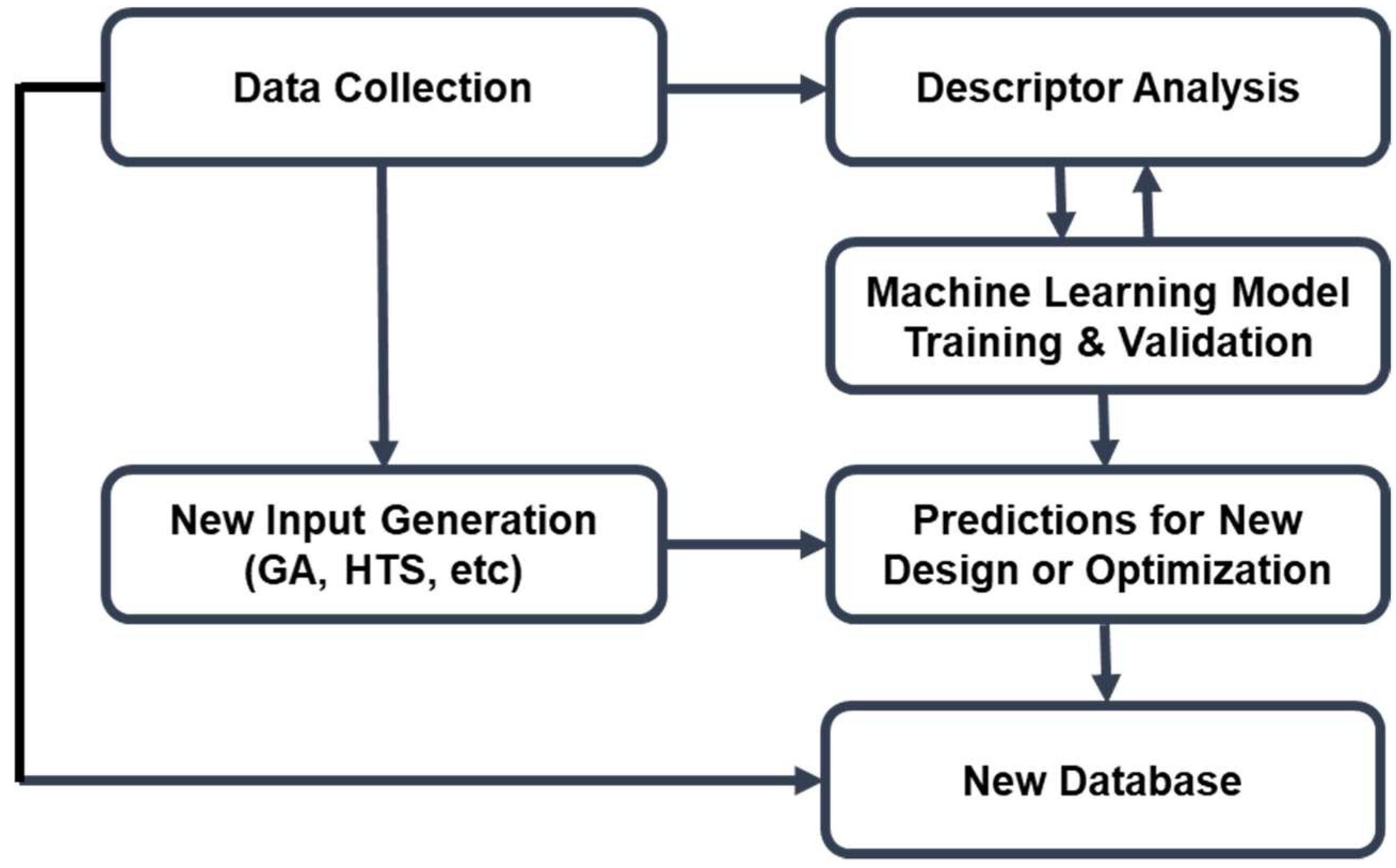
Figure 6. Flow chart of the data-mining for processes in natural science and engineering applications.
Figure 6. Flow chart of the data-mining for processes in natural science and engineering applications.
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Li, H.; Zhang, Z.; Zhao, Z.-Z. Data-Mining for Processes in Chemistry, Materials, and Engineering. Processes 2019, 7, 151. https://doi.org/10.3390/pr7030151
AMA StyleLi H, Zhang Z, Zhao Z-Z. Data-Mining for Processes in Chemistry, Materials, and Engineering. Processes. 2019; 7(3):151. https://doi.org/10.3390/pr7030151
Chicago/Turabian Style
Li, Hao, Zhien Zhang, and Zhe-Ze Zhao. 2019. "Data-Mining for Processes in Chemistry, Materials, and Engineering" Processes 7, no. 3: 151. https://doi.org/10.3390/pr7030151
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.